


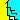






Application de CART.
Une dernière catégorie de méthodes utilisée dans cette étude comparative est représentée par la méthode des arbres de classification et de régression CART. Développée par Breiman et al (1984), elle remplace souvent les autres méthodes de classification explicative telles que CHAID (Kass, 1980) ou AID (Sonquist, 1970) car elle n’est pas limitée à des variables indépendantes catégorielles (nominales) mais accepte aussi des variables continues[3]. La fonction rpart, c’est-à-dire l’implémentation de la méthode CART en R a été utilisée pour obtenir un arbre de classification et de régression à partir des données.
Il s’agit d’un arbre de classification car la variable dépendante est catégorielle (achat/non-achat) et que l’on traite les données individuelles. Le modèle est obtenu en utilisant toutes les variables RFM ; le critère de séparation est la réduction de l’entropie, un minimum de 20 observations dans un nœud terminal (feuille), un paramètre de complexité de 0,001 et une profondeur maximum de l’arbre de 30.
L’arbre à 26 noeuds de la saison 7 utilise dans l’ordre les variables R1, F1, et R2 pour séparer les segments ; les variables F2 et R2 apparaissent à des niveaux inférieurs dans la structure de l’arbre. La variable F1 est le plus souvent en première position, suivi par R1 dans la majorité des saisons analysées. Cela est en accord avec le poids de ces variables dans les modèles logit et probit ajustés.
Dans CART tous les clients qui appartiennent au même segment sont traités de la même manière contrairement aux autres méthodes qui attribuent un score de vraisemblance de réponse différent à chaque client, ce qui leur donne une meilleure granularité par rapport à CART.