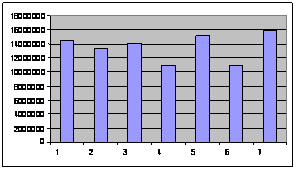
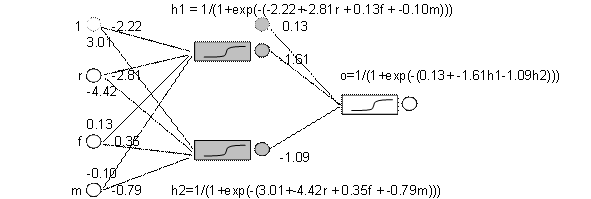
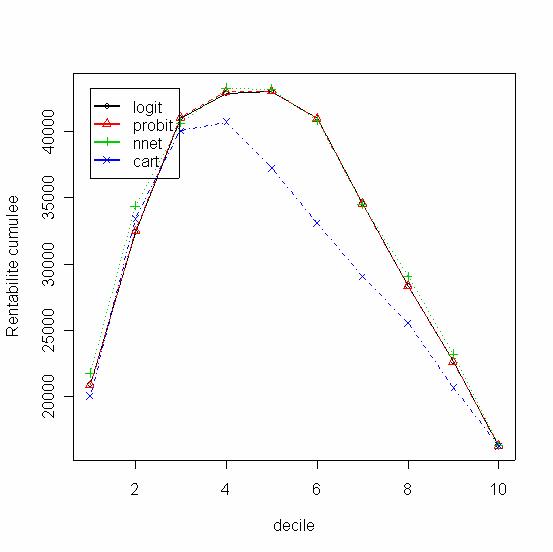
|
|
Bibliographie
Bauer C. L. (1988) A direct mail customer purchase model. Journal of Direct Marketing, 2,16–24.
Bentz Y. et Merunka. D (2000), Neural networks and the multinomial logit for brand choice modellnig: A hybrid approach , Journal of Forecasting, 19, 3, 177-200
Bradley, A.P. (1997), The use of the area under the ROC curve in the evaluation of machine learning algorithms, Pattern Recognition, 7, 1145-1159.
Breiman, L., J. Friedman, R. Olshen, et C. Stone (1984), Classification and Regression
Trees, Wadsworth, Monterey,
Courtheoux, R.J. (1987), Database modeling: Maximizing the benefits, Direct Marketing, 3, 44–51.
Cullinan, G.J. (1977), Picking them by their batting averages’ recency – frequency – monetary method of controlling circulation, manual release 2103, Direct Mail/Marketing Association, N.Y..
Desmet P (1996), Comparaison de la prédictivité d'un réseau de neurones à rétropropagation avec celle des méthodes de régression linéaire, logistique et AID pour le calcul des scores en marketing direct, Recherche et applications en Marketing,11, 2, 17-27
Granger, C.W.J. (1998), Extracting information from mega-panels and high-frequency data, Statistica Neerlandica, 52, 3, 258-272.
Green, D. and Swets, J.A. (1966), Signal detection theory and psychophysics, John Wiley & Sons, NY.
Haughton, D. et S. Oulabi (1993), Direct marketing modeling with CART and CHAID, Journal of Direct Marketing, 7 (3), 16–26.
Kumar, A., Rao V.R., et H. Soni (1995), An empirical comparison of neural network and logistic regression models, Marketing Letters, 6, 251–263.
Kass, G.V. (1980). An exploratory technique for investigating large quantities of categorical data, Appl. Statist., 29 (2), 119-127.
Levin, N. and Zahavi, J. (1998), Continuous predictive modeling: a comparative analysis, Journal of Interactive Marketing, 12, 2, 5-22.
Linder R., Geier J. et Kölliker M. (2004), Artificial neural networks, classification trees and regression: Which method for which customer base? Journal of Database Marketing & Customer Strategy Management,11, 4; 344-357
Lix, T.S. et Berger P.D. (1995), Analytic methodologies for database marketing in the US, Journal of Targeting, Measurement and Analysis for Marketing, 4, 237–248.
Madeira S. et J. M. Sousa (2002) Comparison of target selection methods in direct marketing, European Symposium on Intelligent Technologies, Hybrid Systems and their implementation on Smart Adaptive Systems, Algarve, Portugal, 19 - 21 September.
Magidson, J. (1994), The CHAID approach to segmentation modeling: CHi-squared Automatic Interaction Detection, in R.P. Bagozzi, editor, Advanced Methods of Marketing Research, Basil Blackwell, Cambridge, MA, 118–159.
Mason, Ch.H., Perreault, W.D. (1991), Collinearity, power and interpretation of multiple regression analysis, Journal of Marketing Research, 28, 268-280.
Morrison, D.G., 1966, Interpurchase time and brand loyalty, Journal of Marketing Research, 3, 281-291.
Otter, P.W., H.R. van der Scheer, and T.J.Wansbeek (1997), Direct mail selection by joint modeling of the probability and quantity of response, Som Research Report 97B25, University of Groningen.
Potharst R., Kaymak U. et Pijls W. (2001) Neural Networks for Target Selection In Direct Marketing, ERIM Report Series Research In Management, ERS-2001-14-LIS, 18 pgs.
Rumalhart, D.E. et McCleelland J.L. (1986), Parallel Distributed Processing, MA : MIT Press
Shepard, D. (1995), The new direct marketing: How to implement a profit-driven database marketing strategy, second edition, Business One Irwin, Homewood, IL.
Sonquist, J.N. (1970), Multivariate model building, Institute for Social Research, Ann Arbor, MI.
Spring, . (2001), Quantitative approaches for profit maximizationn direct marketing, PhD. Dissertation, Rijksuniversiteit Groningen.
Swets, J.A. (1979), ROC analysis applied to the evaluation of medical imaging techniques, Investigative Radiology, 14, 109-121.
Thrasher, R.P. (1991) CART: a recent advance in tree-structured list segmentation methodology, Journal of Direct Marketing, 5, 1, 35-47.
Van.den Poel D. (2003) Predicting Mail-Order Repeat Buying: Which Variables Matter?, Working Paper 191, Universiteit Gent, Fakulteit vor Bedrijfskunde, August
Van der Scheer, H.R. (1998), Quantitative approaches for profit maximization in direct marketing, PhD. Dissertation, Rijksuniversiteit Groningen.
Zahavi, J. and Levin, N. (1997) Applying neural computing to target marketing, Journal of Direct Marketing, 11, 1, 5-22.
|