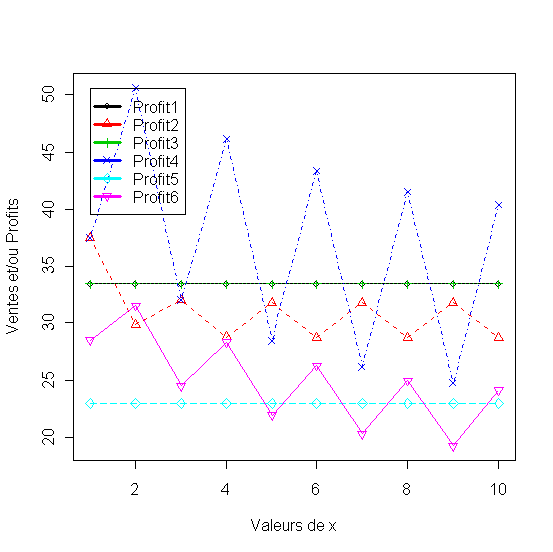
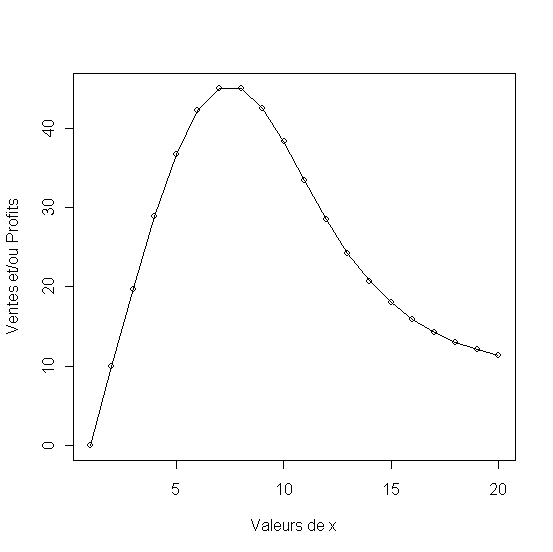
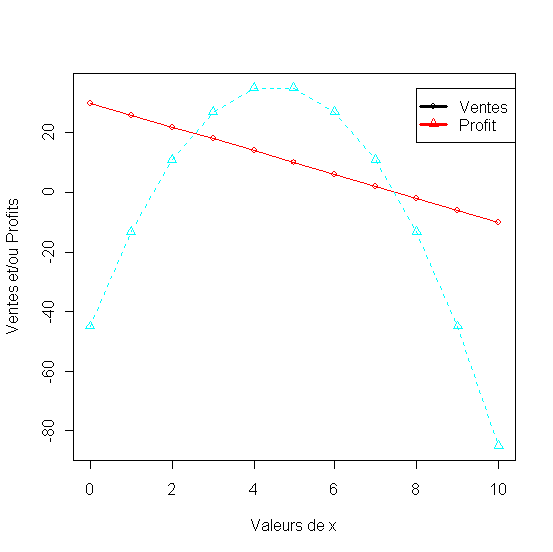
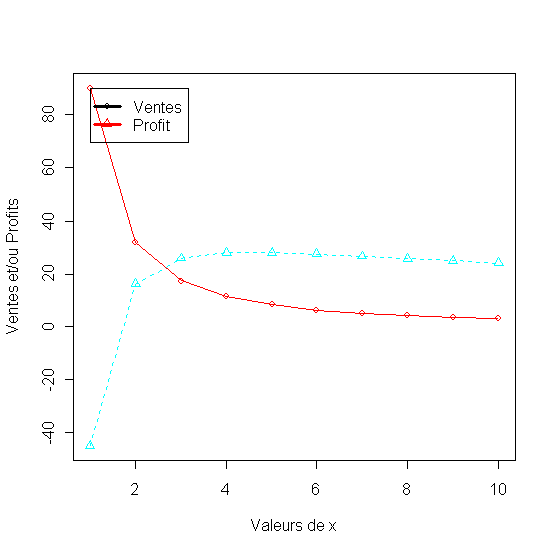
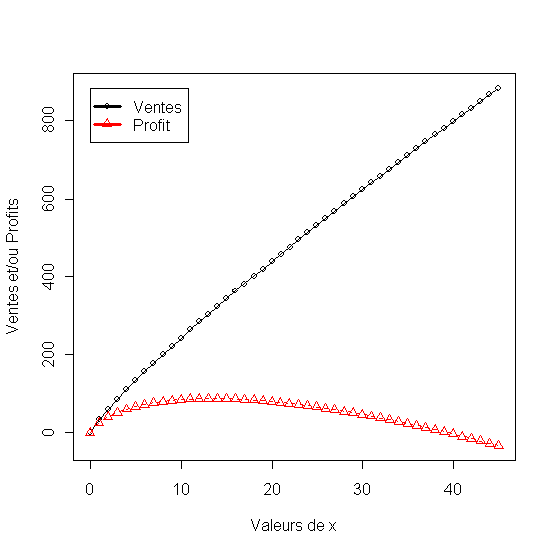
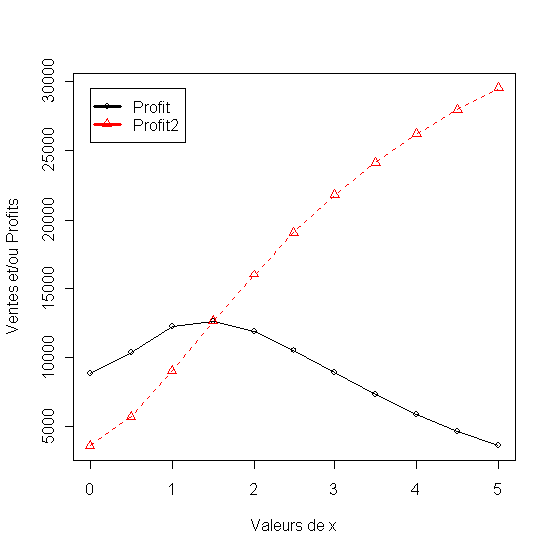
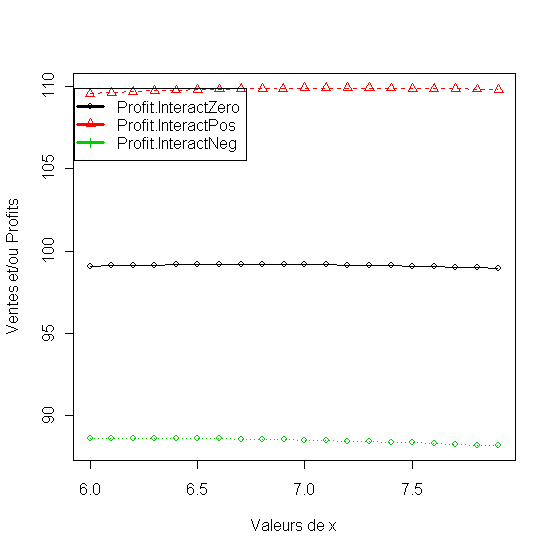
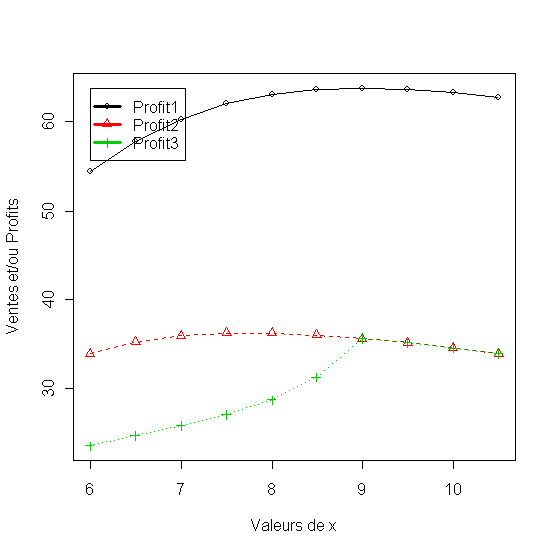
1.
#
attribuer valeurs aux coefs
2.
a1=2; b1=0.5; c1=2; d1=7
3.
a2=0; b2=3; c2=-1.5; d2=0
4.
a4=2; b4=0.5; c4=2 ; d4=7
5.
a5=0;
b5=3; c5=-1.5; d5=0
6.
#
Valeurs des variables marketing
7.
x1<-seq(0,40,1)
# notre pub
8.
#
Variables fixes
9.
#
Notre Prix; Leur pub ; Leur Prix
10.
x2<-rep(2,41); x4<-rep(3,41) ; x5<-rep(2,41)
11.
# Attractions
12.
na<-1*(b1+(a1-b1)*((x1)^c1/(d1^c1+(x1)^c1)))^0.6*(a2+b2*(x2)^c2)^0.4
13.
ca<-1*(b4+(a4-b4)*((+1*x4)^c4/(d4^c4+(+1*x4)^c4)))^0.6*(a5+b5*(x5)^c5)^0.4
14.
#
Part de marché
15.
nms<-na/(na+ca)
16.
df<-data.frame(Notre.Pub=x1,
Part1=nms)
17.
#
Notre Prix; Leur pub ; Leur Prix
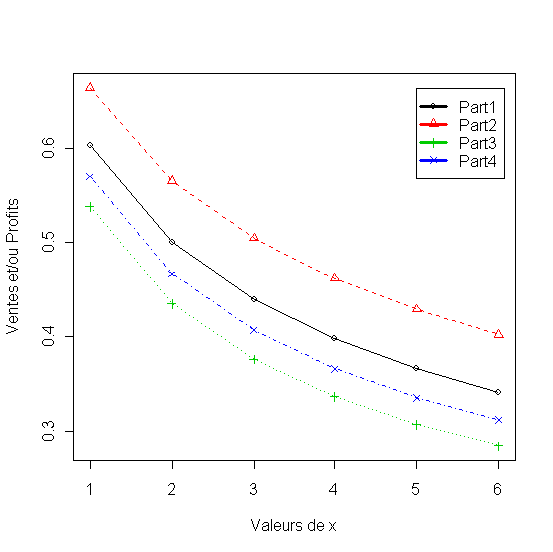
18.
x4<-rep(6,41)
19.
# Attractions
20.
na<-1*(b1+(a1-b1)*((x1)^c1/(d1^c1+(x1)^c1)))^0.6*(a2+b2*(x2)^c2)^0.4
21.
ca<-1*(b4+(a4-b4)*((+1*x4)^c4/(d4^c4+(+1*x4)^c4)))^0.6*(a5+b5*(x5)^c5)^0.4
22.
#
Part de marché
23.
nms<-na/(na+ca)
24.
df$Part2=nms
25.
#
Notre Prix; Leur pub ; Leur Prix
26.
x4<-rep(3,41)
27.
x5<-rep(1.6,41)
28.
# Attractions
29.
na<-1*(b1+(a1-b1)*((x1)^c1/(d1^c1+(x1)^c1)))^0.6*(a2+b2*(x2)^c2)^0.4
30.
ca<-1*(b4+(a4-b4)*((+1*x4)^c4/(d4^c4+(+1*x4)^c4)))^0.6*(a5+b5*(x5)^c5)^0.4
31.
# Part de marché
32.
nms<-na/(na+ca)
33.
df$Part3=nms
34.
#
Notre Prix; Leur pub ; Leur Prix
35.
x2<-rep(1.6,41)
36.
x5<-rep(2,41)
37.
# Attractions
38.
na<-1*(b1+(a1-b1)*((x1)^c1/(d1^c1+(x1)^c1)))^0.6*(a2+b2*(x2)^c2)^0.4
39.
ca<-1*(b4+(a4-b4)*((+1*x4)^c4/(d4^c4+(+1*x4)^c4)))^0.6*(a5+b5*(x5)^c5)^0.4
40.
# Part de marché
41.
nms<-na/(na+ca)
42.
df$Part4=nms
43.
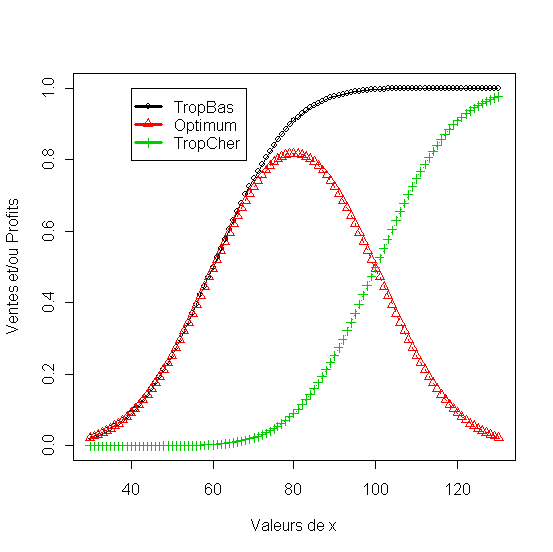
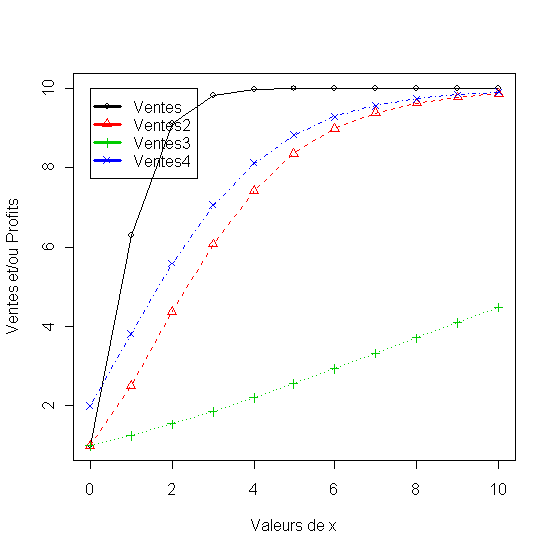
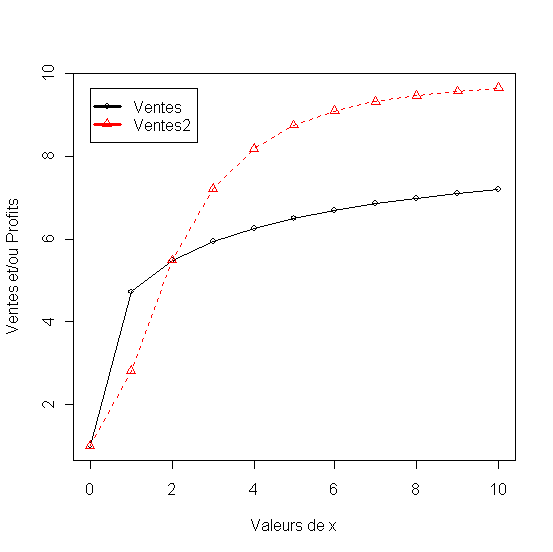
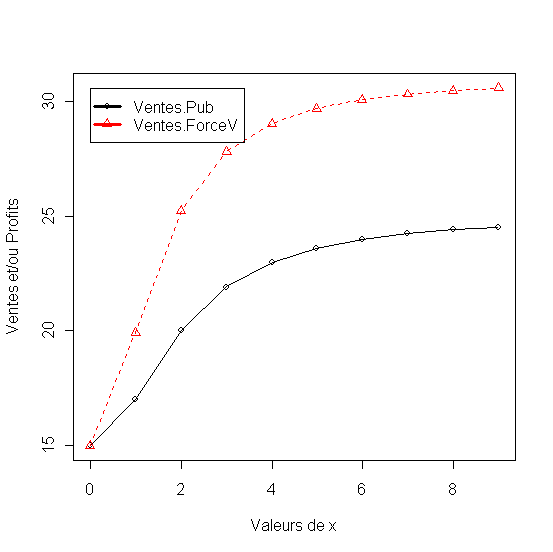
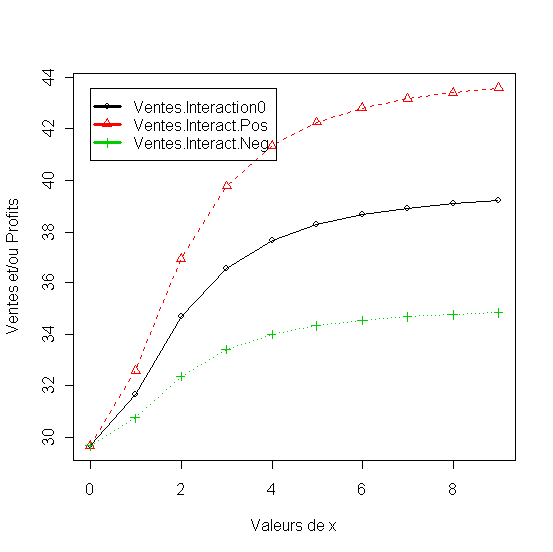
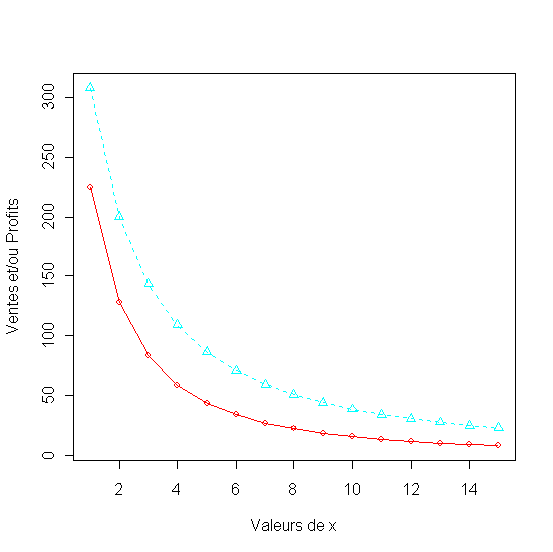
matplot(x1,
df[,2:5], pch = 1:4, type = "o", col = 1:4,xlab="Valeurs de
x", ylab="Ventes et/ou Profits"
44.
legend(min(x),
max(df[,2:5]),names(df)[2:5], lwd=3, col=1:4, pch=1:4)

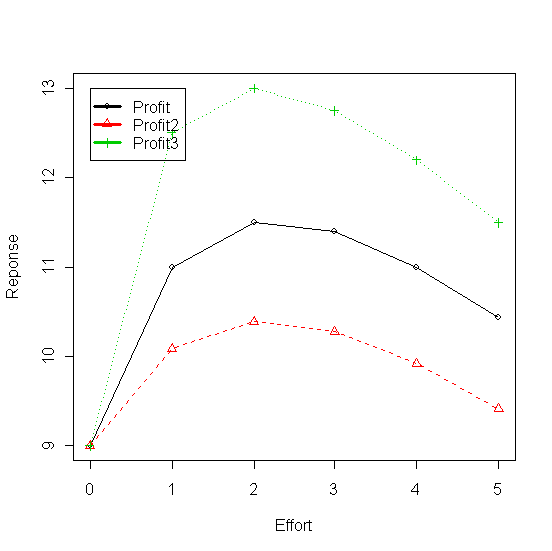


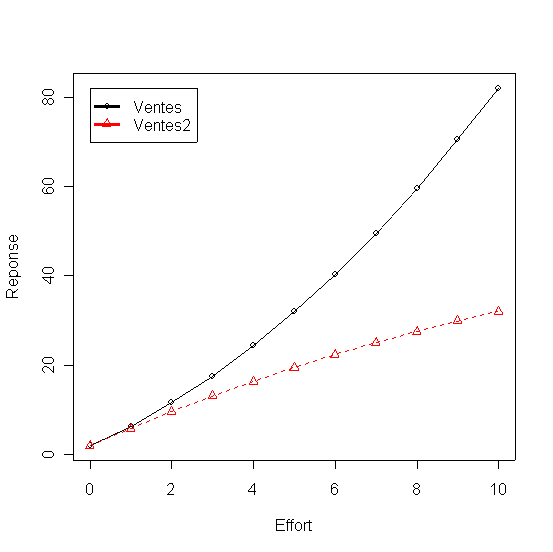
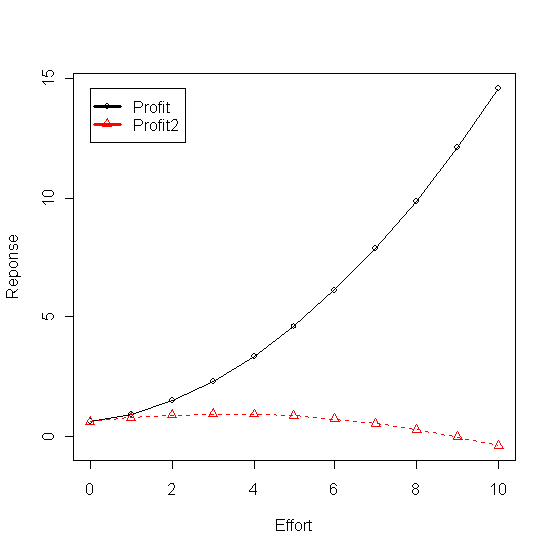
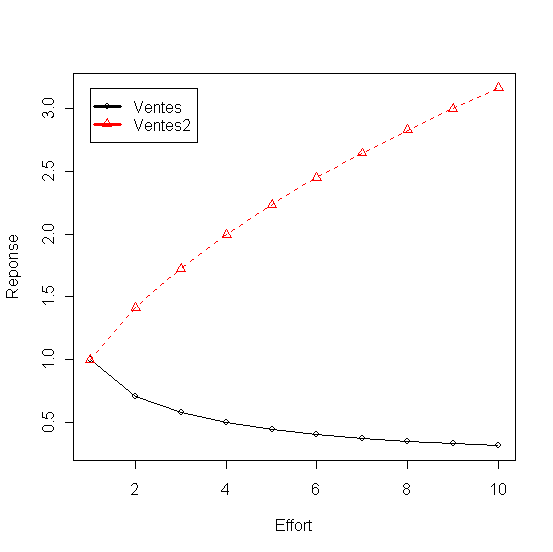







 + ei*
+ ei*